 今回のOracleデータベース10gは、バイオインフォマティクスの一連の処理を、可能な限りデータベース内だけで完結させようとの発想で開発されたものだという。同社は、ファイルの受け渡しをベースにしている現在の研究プロセスでは、複数のポイントでセキュリティ面の危険があったり、間違いが入り込んだりする可能性があると指摘。Oracleデータベース10g内部だけで研究ワークフローを完結させれば、セキュリティの問題はなく、高いパフォーマンスを実現できるとしている。
今回のOracleデータベース10gは、バイオインフォマティクスの一連の処理を、可能な限りデータベース内だけで完結させようとの発想で開発されたものだという。同社は、ファイルの受け渡しをベースにしている現在の研究プロセスでは、複数のポイントでセキュリティ面の危険があったり、間違いが入り込んだりする可能性があると指摘。Oracleデータベース10g内部だけで研究ワークフローを完結させれば、セキュリティの問題はなく、高いパフォーマンスを実現できるとしている。
Oracleデータベース10gがバイオインフォ向けの新機能を搭載
統計関数の拡張、ネットワークデータモデル、BLAST内蔵など多彩
2003.12.27−オラクルの新型データベース製品「Oracleデータベース10g」に組み込まれているバイオインフォマティクス向け新機能の概要が明らかになった。12月17−18日に東京ビッグサイトで行われた“オラクルワールド東京”のコンファレンスの中で日本オラクルが公開したもの。大量の遺伝子情報を利用した統計解析やデータマイニングのための特別な機能を内蔵しているほか、生物学的な相互作用情報を効率良く格納・検索できるようにする「ネットワークデータモデル」の採用、塩基配列の相同性検索で多用されるBLASTアルゴリズムをカーネルに埋め込むなどの特徴を備えている。
今回のOracleデータベース10gは、バイオインフォマティクスの一連の処理を、可能な限りデータベース内だけで完結させようとの発想で開発されたものだという。同社は、ファイルの受け渡しをベースにしている現在の研究プロセスでは、複数のポイントでセキュリティ面の危険があったり、間違いが入り込んだりする可能性があると指摘。Oracleデータベース10g内部だけで研究ワークフローを完結させれば、セキュリティの問題はなく、高いパフォーマンスを実現できるとしている。
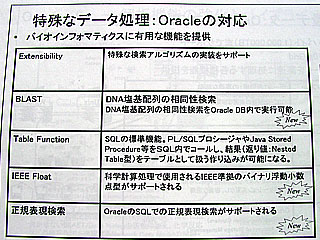
バイオインフォマティクス分野で利用されるさまざまなデータタイプに対応しており、SWISS-PROTなどで配布されているXMLデータをドラッグ&ドロップ操作だけで簡単に取り込めるようにする“XMLデータベース機能”や、電気泳動のイメージや電子顕微鏡写真などを画像データを格納できる“インターメディアイメージ機能”、生物学的パスウェイなどのグラフで表現された相互作用情報の論理的ネットワークを格納・分析できる“ネットワークデータモデル機能”、フラットファイルをオラクルのテーブルに格納されたデータであるかのように検索できるようにする“エクスターナルテーブル機能”−を備えている。
とくに、ネットワークデータモデルは今回から搭載された新機能で、京都大学化学研究所が作成しているパスウェイデータベースKEGG/PATHWAYに採用されている。これは、代謝系、シグナル伝達系、たん白質複合体などの100枚以上のリファレンスマップをベースに、生物種ごとのパスウェイ情報を再構築しているもので、代謝化合物と酵素反応の相互作用関係をグラフのかたち(http://www.genome.ad.jp/kegg/java/Manual/markupec_help.html)で扱うことができるのが最大の特徴。Javaを使った解析ツールが組み込まれており、任意の二つの化合物をつなぐ最短経路やすべての経路を探索し、グラフ上に重ねて示すことができる。経路が通らない場合でも、他の生物種で知られている酵素を経由すればパスが通るのではないかなどの高度な考察が可能になる。
このようにグラフデータを扱うことができるため、ネットワークデータモデルはパスウェイデータのモデル化に最適な機能だといえ、階層的なデータ構造の定義も可能。KEGGで構築されている代謝系のデータ以外にも、たん白質相互作用などいろいろな生物学的ネットワークをデータベース管理できると期待される。
一方、BLAST解析をOracleデータベース10g内だけで行えるようになったことも今回の大きな目玉の一つだ。米バイオテクノロジー情報センター(NCBI)から公開されているソースコードをもとに、Oracleデータベース10gにBLASTのコードがカーネルレベルで組み込まれている。従来は、配列データベースから事前に配列情報を抽出し、それに対して索引付けを施し、BLASTを逐次走らせたあとに検索結果を配列データベースにフィードバックするという面倒な手順があったが、10gではオラクル内部に蓄積された配列データベースをそのままBLAST解析にかけることが可能。いわば、BLAST処理がオラクルの中だけでパイプライン化されているわけで、遺伝子研究を大幅にスピードアップすることにつながる。
また、グリッドコンピューティング機能を簡単に利用できることも強みで、配列データベースを分割し、検索処理を並列化することによって、いままで1週間かかっていた検索時間を10分間あるいは1分間に短縮することも可能だという。
遺伝子関連データベースなどを検索する際に正規表現が利用できるようになったことも10gでの大きな特徴となる。Oracle9iまでは正規表現を使うことはできなかった。この正規表現はいくつかの文字列を一つの形式で表現するための表現方法で、非データベース環境でよく利用される。今回利用できるようになった正規表現例としては、「任意の1文字」、「1文字以上の文字列」、「0文字以上の文字列」、「0文字または1文字」、「m文字からn文字の間」、「AかBのいずれかにマッチ」、「グループ化」、「リストのいずれかにマッチ」、「リストのいずれにもマッチしない」、「n番目にマッチするグループ」、「文字列(行)の先頭、末尾」、「キャラクタークラス指定」−があげられる。
さらに、オラクルデータベース内で統計処理やデータマイニング処理も実行可能となった。新たに追加された統計関数とデータマイニングのためのアルゴリズム一覧は下表にまとめた通りである。