 今回のプロジェクトは、文部科学省が選定した戦略目標「分野を超えたビッグデータ利活用により新たな知識や洞察を得るための革新的な情報技術及びそれらを支える数理的手法の創出・高度化・体系化」に基づき、CRESTが進める研究領域「科学的発見・社会的課題解決に向けた各分野のビッグデータ利活用推進のための次世代アプリケーション技術の創出・高度化」の枠組みで実施されるもの。約60件の応募の中からこのプロジェクトを含む2件が採択された。
今回のプロジェクトは、文部科学省が選定した戦略目標「分野を超えたビッグデータ利活用により新たな知識や洞察を得るための革新的な情報技術及びそれらを支える数理的手法の創出・高度化・体系化」に基づき、CRESTが進める研究領域「科学的発見・社会的課題解決に向けた各分野のビッグデータ利活用推進のための次世代アプリケーション技術の創出・高度化」の枠組みで実施されるもの。約60件の応募の中からこのプロジェクトを含む2件が採択された。
医薬品研究から製造までのビッグデータプロジェクトが始動
東大・船津教授らが実施、知識創出基盤確立へ
2013.12.18−科学技術振興機構(JST)の戦略的創造研究推進事業(CREST)に採択された「医薬品創薬から製造までのビッグデータからの知識創出基盤の確立」プロジェクト(研究代表者=東京大学大学院工学系研究科・船津公人教授)が始動した。3つの研究グループに分かれ、2018年度末のゴールを目指す。医薬品の研究から製造までの各段階を俯瞰的にとらえ、ビッグデータを活用した知識創出基盤を構築することで、プロセス全体を効率化・高度化させることを狙いとしている。
今回のプロジェクトは、文部科学省が選定した戦略目標「分野を超えたビッグデータ利活用により新たな知識や洞察を得るための革新的な情報技術及びそれらを支える数理的手法の創出・高度化・体系化」に基づき、CRESTが進める研究領域「科学的発見・社会的課題解決に向けた各分野のビッグデータ利活用推進のための次世代アプリケーション技術の創出・高度化」の枠組みで実施されるもの。約60件の応募の中からこのプロジェクトを含む2件が採択された。
研究代表の船津公人教授は、医薬品の研究開発および製造現場において、データ不足に基づく限界が生じていると指摘する。「創薬を成功させるには、いかに幅広い化合物空間を探索するかが重要だが、実在する化合物のライブラリーは数百万程度。バーチャルライブラリーでもたかだか数千万程度で、しかも合成法がわからないものが多い。また、医薬品としての高い品質を満たしながら経済的・安定的に製造するため、ソフトセンサーを用いてリアルタイムに品質をコントロールすることが注目されているが、ソフトセンサーの統計モデルを構築するのに必要なデータが不足している」という。
そこで、今回の研究では3つのサブグループが「大規模仮想化合物ライブラリーの高度化」(理化学研究所生命システム研究センター・泰地真弘人副センター長)、「大量のたん白質対化合物情報からの創薬指針の抽出」(京都大学大学院薬学研究科・奥野恭史教授)、「製造プラントの安定運転・リスク事前管理・品質安定化のための知識抽出」(東京大学大学院工学系研究科・船津公人教授)−のテーマで活動。それぞれの研究成果を持ち寄って連携を図ることで、“製造段階の適性を考慮した研究開発”と“研究データを利用した効率的な医薬品製造”を実現するなど、プロセスシステム全体を俯瞰したかたちでの効率化・最適化を達成することが目標となっている。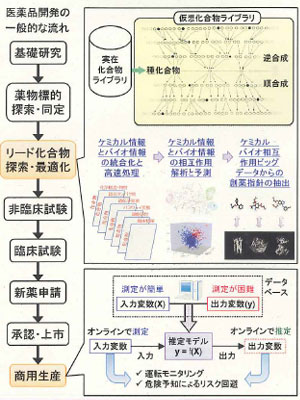
具体的に、各グループの研究内容をみていくと、まず泰地グループは理研のコンピューター資源を生かし、新薬のスクリーニングに利用できる50億件規模の仮想化合物ライブラリーを構築する。とくに、これまでとはケタ違いの構造を発生させるカギは、船津教授らが開発した合成経路設計支援システムに組み込まれたコアテクノロジー。もとのシステムは、入力された生成物の構造から逆合成を行い、前駆体の構造を予測することで、合成経路のスキームを検討する機能を持っている。
このエンジンを利用し、種になる構造を前駆体(逆合成)および反応物(順合成)の両方向へ数段階にわたって展開させることで、大量の化合物構造を生成することが可能。この方法により、40万ほどの種になる化合物から、約50億件の新規性に富む化合物群が得られるという。仮想的に合成を展開するアルゴリズムは、既知の合成ルールをもとにした知識ベースに基づいているので、50億のうちのどの化合物がヒットしても合成経路が最初から明確になっているというメリットがある。
それぞれの化合物に対して、logPなどの物性計算を実施した結果も付け加えてデータベース化するが、格納される情報量が巨大であるため、高速にデータを検索したり可視化したりする技術も並行して開発していくことにしている。
次に、奥野グループは、バイオ関連情報を保有する化合物データを網羅的に収集し、ケミカル情報とバイオ情報の相互作用ビッグデータ解析を可能にする数理的モデルを開発、実際のビッグデータ解析を通じて創薬指針を抽出することを目指す。全体として、奥野教授らが開発したスクリーニング技術である“相互作用マシンラーニング法”(CGBVS)を発展させる方向。ただ、現在のCGBVSが化学構造と物性データ(ケミカル情報)を結合たん白質の情報(バイオ情報)と関連付けているのに対し、今回のプロジェクトはバイオ情報の幅を広げ、遺伝子発現やパスウェイ変動、細胞活性、臨床情報なども加味したモデル化を図ることを新たなチャレンジとしている。
3番目は船津グループで、プラントの運転データをビッグデータとして活用するための道をつける。研究ではまず、医薬・化学プラントの大量の運転データを収集し、大規模データベースとして管理する手法を開発する。外れ値やノイズ、冗長な情報を含む運転データを半自動的に処理できるようにし、運転現場からの測定データを刻々と蓄積・更新していく。“半自動化”とするのは、外れ値除去・ノイズ処理・データ圧縮などの過程で、プロセス技術者の経験・知見に基づく判断を加えられるようにするためだという。実際に協力企業から運転データを集めてデータベースを開発する。
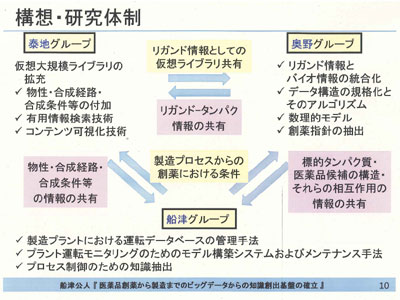 そして、このデータベースを利用して、ソフトセンサーモデルやプロセス状態監視モデルを構築。最新データを反映させてモデルを最適化する仕組みも加える。これにより、ソフトセンサーが有効成分含有量などを把握することで製品品質の安定化が達成されるほか、プロセス状態監視モデルを通したモニタリングによって、プラントの異常検出およびその原因の診断が可能になり、プラントにおける各種リスクを最小化することにつながるという。
そして、このデータベースを利用して、ソフトセンサーモデルやプロセス状態監視モデルを構築。最新データを反映させてモデルを最適化する仕組みも加える。これにより、ソフトセンサーが有効成分含有量などを把握することで製品品質の安定化が達成されるほか、プロセス状態監視モデルを通したモニタリングによって、プラントの異常検出およびその原因の診断が可能になり、プラントにおける各種リスクを最小化することにつながるという。
3つの研究グループは随時研究成果を交換し合って、それぞれの研究内容にフィードバックさせる。成果物については、特許申請や論文発表を行ったのちにすべてを公表していく考えである。船津教授は、「ビッグデータはまだ話題先行で、実際の革新的なアプリケーションはこれからの段階。本研究を通して化学分野におけるビッグデータ活用の実例を示してみたい」と話している。
******
<関連リンク>:
科学技術振興機構(CRESTのトップページ)
http://www.jst.go.jp/kisoken/crest/index.html
理化学研究所(生命システム研究センターのトップページ)
http://www.riken.jp/research/labs/qbic/
京都大学大学院薬学研究科(薬学オープンイノベーション部門のトップページ)
http://pharminfo.pharm.kyoto-u.ac.jp/index.html
東京大学(化学システム工学専攻・船津研究室のホームページ)
http://funatsu.t.u-tokyo.ac.jp/
http://www.chemsys.t.u-tokyo.ac.jp/laboratory_funatsu.html